
Moving to Substack
Gabor Csapo - July 2018
While this personal website was great to experiment with visual design, it obviously not the best way to reach people. During college, writing was more of a thought exercise, but as I'm graduating some of my projects are ripe enough for the world out there. Follow me on Substack for more.

Exponential Development
Machine Learning Art - Gabor Csapo - 3. Feb. 2018
Reading the AI Revolution article, one quote really stuck with me from computer scientist Donald Knuth: “AI has by now succeeded in doing essentially everything that requires ‘thinking’ but has failed to do most of what people and animals do ‘without thinking.'”
After reading this line, the evolution of the human mind strikes me as a slow iterative learning process that optimizes our brains for the tasks that it is required to accomplish (, write, type…). Some ancient skills are optimized to the extent that we unconsciously do them with minimal training (walk, identify objects, recognize faces), but there are “modern” tasks that we are only in the process of figuring out. The problem is that as technology evolves with exponential speeds, our brains that need hundreds of thousands of years to adapt, will never catch up. The new goal of technology and human-computer interaction will be to adapt to human limitations and to augment them. The accelerating progress is also calling for a reformed education that is aimed at rapid learning. The paper clips game, is trying to show us how unleashing AI can destroy humanity if left uncontrolled. Technology cannot advance infinitely fast without overtaking humanity is intelligence.
In response to Part 2 of the article I have mixed feelings about the uncertainty of the future. The article talked about concept that I myself have been thinking about for some time. First, the idea that our brain are just made up of small/big neural nets for every task we encounter. I imagine these neural nets to be rewirable and reprogrammable for new tasks and behaviours, but I guess we have only a limited amount of training time (youth) so we should make use of it. The other fascinating concept is how qualitative differences between intelligence levels are hard to imagine, but provide such an incredible evolutionary advantage. As the author explains, chimps can see skyscrapers, can see that humans are working around it, but will never be able to think on an abstract level that humans are building the skyscraper and in fact any animal could build it. This is why humans came to dominate and why humans will be dominated by AI or morphed into AI in a few decades. On the other hand, I didn’t think of how artificial super intelligence (ASI) could potentially give us immortality. Moreover, I never had the crazy idea that since I will die anyways, my only chance to survive is ASI and therefore I should fight with all my energy to achieve it.
Assited Creation 3.0
Machine Learning Art - Gabor Csapo - 26. Jan. 2018
The purpose of technology is to augment and enhance human capabilities. This is the value proposition of every meaningful piece of technology, and I hope to one day create a tool to extend human abilities as part of the artist/computer scientist movement.
We are all direct products of the democratization of technology and as a result there has been a big shift on how people approach creation. Previously, people regarded creation of anything as a highly professional activity that requires years to master the necessary skills and gather experience. In the modern world creation is often regarded as an easy everyday task. The internet is full of tutorials that make advanced mathematics, painting, and music seem like a piece of cake.
Due to the availability of assisted creation systems and tutorials, the value of creation plummets. It is worrying that many formerly highly valued professionals like photographers are struggling, but I firmly believe that as we create tools and the tools shape us we will always find purpose and task for ourselves. This new purpose, however, becomes higher and higher level and more disconnected from the real world. We are clicking a mouse to paint on a canvas, or to play a drum set instead of using our hands. I wonder how that will change people’s relation to their environment.
On a different note, inspired by the Google Quick draw game, I created this dynamic time warping model with 2 iniputs and 3 output classes. The predicted classes are "chair", "circle" and "letter P". The training and test data was drawn by me in processing, and the output goes through the localhost to another processing window, which displays the name of the class.

Visual Gender Bias on the Web
Politics of Code - Gabor Csapo - 11. Dec. 2017
Only 24 percent of the people heard or read about in print, radio, and television are female, according to a 2010 Global Media Monitoring Project1 . This bias in the media will impact, for example, the dominant ideals, expectations about beauty, age, gender, and what is considered normal in a society.2 While the issue of representation in traditional media has been studied in the past, the issue is less understood on the new medium, the internet. To bridge this gap, I will propose a quantitative method to investigate the visual culture on the internet. While there have been manual and textual analyses 3, 4 , I could not find another project that attempted to analyze the gender bias on the internet from a visual perspective, which is what gives this project its significance and novelty. The reason for this lack of visual analysis might be because it is only recently that with the new developments in convolutional neural networks (CNN), computers have the vision and power to assess female and male faces on scale with high precision. 5 Relying on these CNNs, I created a tool to count female and male faces on website during a browsing session.
Results of my browsing in Dec. 2017
I hypothesised that websites would be biased towards a single gender based on the target groups and content of the website. To measure the differences, I designed a multi layered system based on a chrome extension collecting images, a node server, calling python scripts processing images, and a D3 JS front-end to visualize the results. As an introduction I will walk through each component and what it does.
Chrome extension
Through the Webrequest Chrome API, any chrome extension can get permission to see and collect web request made to servers. My extension is listening for these requests made, and saves the ones that have an image data type. Once we have 150 urls or the user presses the “send” button on the popup, the list of urls is sent to the server to be evaluated. In the popup, you can also start/stop recording, request the results of your data collection, and empty the storage.
Server
The heart of the application is a node server, that listens for incoming urls. If received, it will download every image that is above 5kB (smaller than that is too small to find faces), and call a python script to evaluate whether the images contain faces and what their genders are. I don’t filter out duplicates, because even if a user opens BBC 5 times a day and sees the same male face, that face is still viewed five times. If a visualization is requested from the server, it calls another python process, to create the information visualization for the front-end component of the project. Then it sends an html as response.
Python scripts
Using a pre trained CNN by the B-IT-BOTS robotics team 6, the script first counts the number of male and female faces presented in each image. The robotics team reports accuracies of 96% in the IMDB gender dataset and their model has been used in thousands of projects. Understandably, most pictures don’t contain faces, therefore they are deleted. The second function of this script is to prepare the visualizations created from these images. Using DLIB and OPENCV, the script crops each image to the face, detects landmark points on the images and creates a distortion that corresponds to the average of these faces 7. It also creates a tile of 100 images to see specific faces.
Front-end
The user is presented the count of each gender, and an interactive scatterplot made using D3JS for each host domain. Each host domain corresponds to a website in general, but it takes a little guessing to find out which one. You see both the results of your logging and a summary of every user. Additionally, I include the average of the faces you were presented, and the image tile. The former would be more useful to see the ethnicity and average skin color, but that is currently not the aim of this project, although it would be a great extension of it in the future. The image tiles could be improved by writing on them what the computers gender guess was. That way the user would have a visual proof of how accurate the system really is.
User testing
Tested 5 close friends from Asian, European and American backgrounds, 3 female, 2 male. Being liberal arts students they all found the project very interesting, but they also revealed holes in my design. The installation is currently very difficult as they have to download the extension from my website, enable developer mode and load the extension. Uploading the project to the paid Chrome Webstore would ideal, but I will need to explain the goal of the project clearly through examples and effective text, because the users were not absolutely clear how the whole project worked even after I explained them. I expected them to grasp my concept quicker, but testing readjusted my expectations. The user testing also made me realize that I need way more processing power. Currently on my dual core server, I don’t think I could handle more than 5 people at a time, because the machine learning and image processing is really demanding. The biggest overhead is loading the libraries. As for the visualization, I will have to improve labelling, apply more effective text, and simply have a section just to explain the project. People didn’t realize what the scatterplot meant, didn’t guess the origins of the hosts at first. The zooming on the scatterplot is good and bad at the same time, I definitely need to set a max zoom. They also asked me to put new metrics up, like comparing .com, .de, .cnn, etc… One big question was privacy, and everybody was really surprised how easily I can grab their private images and download them on my server, which created some concern in them, so I deleted all their pictures after the testing was done.
Issues
A big issue is the number of libraries needed for the python scripts. Every library depends on 6 other python modules, and controlling the versions and installation environments is a difficult task. In the process, I installed a lot of redundant libraries, and simply the project should be made simpler. I learnt a lot about concurrency in javascript in the project, but it is still not absolutely perfect. Unfortunately, cached images are not requested from the internet, so for the best result, the extension should empty the cache before starting to use the system. Thirdly, the project is wildly violating privacy by downloading and storing + displaying private images of anybody. Changing the platform of the project would a great way to resolve many issues. Currently the analysis part is centralized into the server and the extensions funnel data to the server. A better approach would be to package up the project and make it available for anybody to run and analyze his/her own browsing habits. Only the numbers would be sent to the central server to keep track of the global results. This distributed approach would not only resolve the privacy issue, but also the computational burden. It is not scalable to offer an expensive computation service for free for potentially hundreds of users, but if installation is sufficiently easy, the users can use their own computers.
Learning outcomes
The project gave me a lot of though days, but I learnt about JS concurrency, data processing, applying machine learning algorithms, D3, chrome extensions and image processing. Unfortunately, I will have to shut down the project eventually, as it is using too much of my virtual machine, but I hope to develop it in the future to be able to release it open-source or at least to archive it in a video.
Discussion
The goal of the project is measure the visual gender bias on the web, but what were the results and why do they matter? For me the most interesting subjects for analysis were 1. company website, 2. social media, 3. news. Unfortunately, I don’t have the resources for an extensive analysis of the web landscape but after using the tool for 1 week and collecting 2700 faces, I have some fascinating remarks. Companies that really care about diversity invest into their web design. Websites of Goldman Sachs, Morgan Stanley all have a pretty even, sometimes female dominant visual culture. Eastern/Central European news perform terribly with most of their images being of men, while Western news are slightly better in this respect. My instagram feed seems to be female dominant, which might arise from the facts that the platform is mainly female dominant 9 . However, I would be very careful with these conclusions, as the observation period was very small and during development it did not reflect my browsing habits, as well as I was the only main study subject. To create robust studies, we need more users, more metrics, and a lot of time.
We live in male-dominated world. Women are underrepresented at major institutions, universities, top businesses, and in government. Web design is an area, where the proper education of professionals can highly impact the image of women in society. Depicting everything with one gender is a baseless representation that exists only to serve itself, which can be interpreted through the argument of Baudrillard’s description of simulacra and a system of simulation. “Simulacra are the baseless images / signs / symbols / products that then propagate a system that demands its own worthless reproduction. Awareness of this degenerative process helps to inoculate us from being part of a simulation problem and to be good stewards of organizational processes.” 11 I hope that measuring and being able to compare websites’ visual culture could spur a conversation to break out of the gender simulacra and to make the internet a more inclusive visual space.
Sources:
1. Global Media Monitoring Project 2010, https://cdn.agilitycms.com/who-makes-the-news/Imported/images/reports_2010/global/gmmp_global_report_en.pdf
2. Rakow, F. & L. Wackwitz (2004). Feminist Communication Theory: Selections in Context. Routledge.
3. Global Name Data: https://github.com/OpenGenderTracking/globalnamedata
4. Adrienne LaFrance, I Analyzed a Year of My Reporting for Gender Bias and This Is What I Found, 2013 Medium.com
5. Adit Deshpande The 9 Deep Learning Papers You Need To Know About https://adeshpande3.github.io/adeshpande3.github.io/The-9-Deep-Learning-Papers-You-Need-To-Know-About.html
6. Arriaga, Octavio, Matias Valdenegro-Toro, and Paul Plöger. "Real-time Convolutional Neural Networks for Emotion and Gender Classification." arXiv preprint arXiv:1710.07557 (2017).
7. Steyvers, M. Behavior Research Methods, Instruments, & Computers (1999) 31: 359. https://doi.org/10.3758/BF03207733
8. https://www.diversityinc.com/diversity-management/ask-diversityinc-who-has-the-best-website-for-diversity/
9. https://www.pewinternet.org/2015/08/19/the-demographics-of-social-media-users/
10. https://www.mckinsey.com/business-functions/organization/our-insights/why-diversity-matters
11. Matt Strohmeyer, https://medium.com/30-pages/reading-2-2-simulacra-and-simulation-jean-baudrillard-c0f1cb5227d

My quick view on green transformation
Politics of Code - Gabor Csapo - 4. Dec. 2017
Pollution is one of the major tragedies of the commons that we need to avoid to survive as a species. The human race functions as a system and as every system there are leverage points that we need to adjust in order to tackle the issue. We can change the parameters (taxes, standards), buffers, flows, feedback loops, as discussed indirectly by Brett Victor, but these have week effects. Real success depends on how well we can support a paradigm shift in higher level leverage points. We need to change the rules of who makes rules. As long as corporations dictate trends, we will not push forward for a cleaner future until that becomes economically viable, which will never happen if there is no initial investment. The best way to achieve such a transformation is to change the mindset that created the previous system. I truly believe that education can profoundly impact the way individuals think, and that has to be utilized. If I never learnt about the social context that technology is creating, I would have never thought about the consequences of my creations.
Two specific leverage points that captured my imagination is to create a business world where green tech is taken seriously by establishing funds and incubators and to manipulate large corporations who can drive the shift. First, we need to promote green tech incubators that have the ability to capture the minds of the brightest to solve the problems that actually matter for the future. Available funding would make people’s goals to innovate in the field, and hopefully people would start to think about green tech as a serious business and not merely a toy field. As I. Burrington explains in the case of data centers, industries are fragmented between a few big and a lot of small players. While it is impossible to persuade thousands of small companies to adapt green tech, it prove possible to push Facebook and Google to buy sustainable energy for their data centers. I found it empowering that Green peace could achieve this in the case of Facebook, and I believe we should learn from this and find new ways to jumpstart the shift at big companies.
Instead of just solving specific green engineering problems at hand, we need to focus on finding a solution to setting people in motion to reevaluate the constant growth model and value sustainability instead. That is the hardest challenge of the 21st century as we have romanticized wealth, development, and progress for more than 2 centuries, and it is also part of our nature to always want more.

Speech, Writing, Code
Politics of Code - Gabor Csapo - 25. Nov. 2017
Humans have been using speech for thousands of years and through that we developed an understanding of what features it has and what it can be used for. Express emotions, give commands, connect with people. The same way after the invention of writing, it took time but we eventually understood what written symbols can express and how it can be used to record information, tell stories, or to communicate with distant people. Code, a new emerging system for creating signification, is waiting to be understood by society as large. N. Katherine Hayles in her paper Speech, Writing, Code: Three Worldviews helps us understand how code exceeds and is different from speech and writing.
The idea that struck me the most is the asymmetry between the source and the target of code. Speech and writing are meant to transfer thoughts between multiple human minds, and therefore optimizing the communication for one means optimizing it for the other as well . Meanwhile, code has an asymmetric relation between the two parties. We have human minds translating their thoughts into voltage signals. There is a myriad of layers between the two to help with the translation and we can see a trend to abstract more and more of the machine language to create code that is more naturally understandable to the human mind.
Until now, our thoughts only lived in our heads, or were recorded on paper. W can convince people to act upon the thoughts we send them on paper or on speech and create physical change, but ultimately thoughts never lived in the world. Code is the first language that is executable. Humans write down ideas through code and then physical machines in the outer world without minds execute these thoughts on our behalf. Code is a “mind amplification” that captures and executes human thought in the physical world. With an analogy to a painter we no longer need to paint using a brush. We can “tell the brush what we want” it will do it, as in the case of the famous one-liner: 10 PRINT CHR$(205.5+RND(1)); GOTO 10.

Internet Copyright Licenses
Politics of Code - Gabor Csapo - 20. Nov. 2017
Copyright licenses can be a really hairy topic. For most of my life, I never bother looking up what all the licenses like MIT, Apache, GPL, BSD, CC, etc actually mean, but some of my recent readings on ownership inspired me to research some of the most common licenses. Licenses are granted by authorities in order to set limits to the usage and redistribution of a creator's work. The above mentioned licenses differ in their takes on copying, modifying, distributing, sharing alike and derivative work. Below I provide a quick non-professional overview of some differences between license.
Creative commons (CC)
Creative commons is actually a collection of licenses by itself. These licenses are a combination of the following attributes: Attribution (author must be credited), ShareAlike (all derivative work must be shared under the same copyright), NonCommercial (only non commercial use allowed) and NoDerivs(meaning no modifications are allowed when sharing). As an example, Wikipedia uses a CC Attribution-ShareAlike license, which essentially means you should credit authors and share your work derived from Wikipedia with the same license.
GNU General Public License
It was founded on the principle that we should be free to use, change, share and share changes to free software. No matter how the software is distributed, it HAS to remain free. This concept is called “copyleft”. A GPL license is very restrictive in the sense that everything has to be open, which doesn’t leave much freedom to somebody who wants to create proprietary software based on GPL licensed work.
Apache License 2.0
This license is more flexible. The source code of derivative work doesn’t need to be public, and can be published under any other license, but similarly to GPL, changes have to be documented.
MIT License
The most open license, which basically puts the work in the public domain and permits anyone to use it in any way. This is probably the most popular open source license.
Berkeley Software Distribution (BSD)
BSD is very similar to MIT, except a clause that prohibits to use the original creators trademark without prior permission. A lot of people know about BSD because of Facebook’s controversial copyright decisions around their open source projects like React. They wrote the BSD+ license building on the BSD, but extended it with clauses that heavily protected Facebook's interests. Luckily, they recently decided to change their policy and switched to the MIT license after realizing the drawbacks of these clauses.
Arctic Expedition Report
Greenland - Gabor Csapo - 19. Nov. 2017
This August I had the opportunity to join climate scientist Prof. David Holland’s team on an expedition to the Jakobshavn Isbrae. Our field trip was part of an annual data collection mission for the Center for Sea Level Change, whose long-term mission is to understand past, present and future sea level changes. The team travelled to West Greenland to study the movement and breaking of ice at the Jakobshavn Isbrae, a major ice outlet in the Northern hemisphere. Glacier calving is a poorly understand process and therefore often missing or misrepresented in computer models and predictions. The goal of Prof. Holland’s research is to improve computer models based on appropriate observations. During the 10 day expedition seismic information was collected, radars and cameras were deployed as every piece of collectable information is valuable in the data analysis phase that follows the field trip. To support the long-term data collection effort, last year the team also built a permanent camp that survived the winter, but required minor repairs.


Sorting equipment at airport & Loading Bell 212 helicopter


Calving front through binocular & Battery pack and controllers


Radome, solar panels and wind turbines & Helicopter takeoff
We started off in Ilulissat, the third largest town in Greenland. First, we prepared equipment that we had to take with us to the camp-site including camping, scientific and personal gear. Once we were out at the fjord we had limited access to resources, so we had to make sure we had everything needed ready to be loaded on the helicopters. In Ilulissat, I was also explained in detail how to set up the TRI radar, that I was specifically interested in. After we were taken on a Bell 212 helicopter out to the ice sheet, we set up camp and started deploying sensors. First we had to fix the blown controller in the battery pack that was built last year to support year long data collection with constant clean energy. Then we assembled the radars, collected data from weather and seismic stations planted last year.
The most valuable aspect of the field trip was seeing the practical use of my academic knowledge by understanding and interacting with real scientific equipment. My most profound realization was the applicability of the skills learnt in Interactive Media courses in actual field research. Previous experience with circuits, soldering, in-series and parallel connections came in handy when we had to understand the wiring of 40 battery packs, 6 solar panels, 4 wind turbines, their controllers and the radar. Also, operating the TRI radar was essentially the same as using sensors and motors in one of my courses. Working alongside Prof. Holland opened up my eyes about the engineering of high-tech scientific equipment, and I believe I wouldn’t have problems operating or debugging such tools in the future.
Having seen the glacier with my eyes provides a sense of scale and a more accurate understanding that will support further projects with CSLC that I’m involved in. I have designed a salinity, temperature, depth data visualization during my junior fall semester that is visualizing some of the data collected during these expedition. I wish to update the tool based on my improved understanding of the data collection and of the mission of the project. I am also involved in a project designing a drone payload to support data collection at the glacier. Our aim is to mount a LiDAR sensor on a drone to allow the 3D mapping of the calving front that can feed into sea-level models. We planned a test flight during the 10 days, but unfortunately the drone lost its stabilisation, which makes it dangerous to fly in high winds. Estimations of height and width of the calving front support our view of the feasibility of the project.
The expedition also introduced me to the methods and challenges of field research. Every day poses a myriad of challenges, that can never mean the end of the mission. As we learnt for instance, a missing cable should not stop the work and can be replaced with makeshift solutions. One has to also learn to work with weather that always turns bad when it should not. The supplied instructions were often wrong, and in one case could have short circuited an equipment any time. Dinner table conversation ended up often as discussions of NSF funding applications, tragic stories in the Antarctica, stories of harsh weather and life in the isolated areas of poles. These conversations introduced me to what working in the field really means. Field research is an incredibly demanding career and all the team members impressed me with their grit, patience, determination to advance science and wide range of knowledge.
The 10 days working alongside such dedicated scientists as Prof. David Holland, Irena and Xianwei, while being kept safe by the caring hands of Denise Holland and Brian has been a humbling experience that I will carry with myself for decades. The expedition served as an incredible interdisciplinary learning experience for a lifetime that I can never be grateful enough for.

End the Marketplaces!
Politics of Code - Gabor Csapo - 13. Oct. 2017
Uber, Airbnb, Amazon Mechanical Turk and other similar “marketplace” apps seem to regulators like a careless, anticompetitive business model that is trying to cheat the system of existing laws. However, these companies participate in a radically new mode of production, the networked information economy (NIE). This term was coined by Yochai Benkler, and refers to individuals taking decentralized individual action to cooperate and create goods and services. This new mode of production was enabled by the easy access to information and necessary capital. NIE has created many open-source software, and is evolving further in the form of the so called “marketplace” apps. To support the spreading of this new business model, it needs to be formalized to create trust between regulators, participants and the “marketplace”, but most importantly, companies should take more responsibility as owners of their networks rather than just marketplaces.
As we all know, Uber and its companions create economic value by mobilizing existing resources to serve demand. Most people have cars and smartphones, which means there is zero capital needed to jump into the business. As part of the NIE, drivers and users are supposedly free-willed actors who decide to cooperate as part of the Uber network, which connects demand and supply. As A. Rosenblat’s paper about the power asymmetries in Uber prove, however, the ownership and control over the design of the network allows unfair exploitation of the service. Uber uses this control for short-term gains, but through that they also create long-term obstacles in the acceptance of the platform.
Uber and Mechanical turk especially has been criticized for being a platform that basically enables to hire and fire people within days with no responsibility as an employer. That is why Uber and its companions thought to be exploitive platforms and are banned in many countries. I would argue, this quick employer turnover definitely has a place in the modern economy, but companies should not be the only ones benefitting from it. “Marketplace apps” need to end. Avoiding social responsibility by hiding behind the “we are a marketplace” mentality, promotes a short-term business model. These companies need to realize that they are network owners, and as the owner they have responsibility over the health of their networks. Uber doesn’t own the drivers or their cars, they own the network of drivers and riders. With that they should also ensure that driver’s have appropriate insurance, clean backgrounds, and pay taxes. It is in their best interest to have a non-exploitive model, that serves not just the company, but also the drivers, riders and society as large. As an idea, for example Uber could create a tighter network, by making the platform invite only. Driver’s would get money for inviting other drivers, but will get a penalty if their invitee breaks the laws, etc… This would create an even tighter community, where drivers are responsible for each other.
But I think it doesn't’ matter that much for Uber, as driverless cars will soon eliminate the need for drivers, and they would become a traditional rental car company.

Existential Crisis
Politics of Code - Gabor Csapo - 6. Nov. 2017
Humans have been occupied by the existential threat posed by our machines for a century at least. It is more and more pressing to understand our purpose as artificial neural networks make the next step in replacing tasks only humans were thought to be able to perform.
Many pessimists say that deep learning is merely a poor imitation of cognitive tasks, and isn’t real learning. Deep learning algorithms are capable of scaling learning tasks based on certain types of experiences (seeing billions of images, profiles, books) to an extent that surpasses our human limitations. An analogy with physical power could be the human arm and a forklift. One evolved to serve a general purpose, while the other was created to solve one specific task, to lift several tons. However, it doesn’t seem like a far fetched idea to use the same electric motors and hydraulic pistons as in the forklift to refine a machine to be able to do what a human body can. Does it mean that it’s a human body? Of course not because it’s made of metal. But the same way, if machine learning can be designed to perfectly imitate cognitive outcomes, they will be able to do the same as humans.
You might say, machines can never be creative, but then most creativity researchers agree that the main secret of creativity is simply gathering experience and combining the ideas gained from them. If we stop thinking of creativity as this magical process, even creativity can seem like something that could potentially be mechanized. Humans developed these superior biological features through thousands of years of evolution, during which we have been molded by people around us, organizations, institutions, and surroundings to develop the best techniques of survival. I’m curios what having machines in this feedback loop would mean. Would the always moral machines, create a peaceful society, or is that against human nature? If society's ultimate goal is to create a peaceful, prosperous environment, do we need machines to enforce that and to overcome the inherently imperfect human nature? What will an AI say about our existence once it becomes more advanced than a model that was trained on movie scenes?

The Greatest Social Experiment
Politics of Code - Gabor Csapo - 31. Oct. 2017
You can have random control trials with a billion people in any city on the planet just by writing a few lines of code. What would you do with this dream of every social scientist? Facebook still seems a little shocked by the amount of data it has amassed, but started conducting experiments to understand what exactly is happening in the Facebook space.
From a scientific perspective, this is incredibly exciting news. Never in history could we conduct such consistent, global and random analysis of human behaviour. I truly wonder what the facebook data hides about mankind. People use social networks to cover up their behaviours and for instance as the author of “The male gazed” article mentions, the majority of facebook's page views can be summed up by “men looking at women”. I wonder what this says about society at large, and whether it is a piece of information everybody should know. In my opinion, for the best outcome we need to know what is happening in our environment and act upon that information, instead of trying to sweep it under the rug. By revealing more about how ideas spread, we could create campaigns to spread positive messages, improve our voting systems and perhaps create a tighter-knit society. Unfortunately, Facebook is a public company, which means most of the data analysis will be devoted to profit making, and also, we have to be careful about making assumptions about society at large based on facebook data. I believe there is a distinct population group who is prone to getting addicted to the attention gained from virtual connections, while others are refusing it instead. Facebook might not be the perfect representation of people, only facebookers.
On the other hand, all this power makes me worried about human rights. Facebook is free to conduct these experiments without our consent simply because we clicked accept on the terms and conditions button when signed up. I believe it is a misuse of their power, as many of us were brought onto facebook as a result of social pressure, which should be taken into consideration. I believe to make these experiments more ethical, we will have to make laws around user privacy stricter. This will hopefully happen sooner than later but currently players in the data business are just trying to figure out what having this much data actually means.

Google's AI Masterplan
Politics of Code - Gabor Csapo - 29. Oct. 2017
Machine learning is the new industrial revolution, which is why all the major technoloogy companies jumped onto the topic. Google, Amazon, Microsoft and Apple are all competing not just for the best algorithms and fastest training, but also for ensuring that they become the center of current and future research. Google's surprise move of open-sourcing Tensorflow, their machine learning library majorly benefitted their efforts to lead the AI revolution and was shortly followed by a number of open-sourced projects. We see competitive market forces drive big corporations toward a model of "openness", with which everyone wins as long as it is easy to move between platforms.
Short history
Machine learning is as old computers are. The first general, working learning algorithm for supervised, deep, feedforward, multilayer perceptrons was published by Alexey Ivakhnenko and Lapa in 1965. Since then every 20 years there was a discovery that sparked interest in machine learning methods, but after exploring the options that were opened up by the discovery, the field went back to oblivion for a decade. The Big Data boom around 2005 gave another boost to research as now scientists had enough computational power and massive labelled datasets to actually train large deep neural networks. The real breakthrough came in 2012, when a group of researchers combining all the recent developments came up with the AlexNet architecture that beat traditional machine learning algorithms in image classification. Their paper unleashed the huge wave of deep learning developments in the past 5 years.
Deep learning went from a niche area of mathematics into the mainstream, where companies quickly saw the commercial value in the ability to automate higher level tasks. Automatically learning features at multiple levels of abstraction allow a system to learn complex functions mapping the input to the output directly from data, without depending completely on human-crafted features. Similarly to the first industrial revolution overcoming the limitations of muscle power, deep learning has the potential of overcoming cognitive limitations in certain tasks, such as image recognition, translation, data analysis, etc… making it the future gold mine. And hence the big tech corporations started a race to dominate the market.
Early development
Machine learning is a complex field. Deep learning is done through frameworks that implement the mathematical formulas behind the different convolution, loss, optimization, classification and various other functions that a deep learning model consists of. In the early days, most frameworks were open-source and were maintained by university research groups, who shared their result along with their frameworks. Researchers’ main goal is to maximize the publicity of their research, which requires them to share their development tools so that their results can be reproduced. This meant that researchers were building on top of each other’s frameworks, which sped up the overall development through open-source contributions. These frameworks made deep learning really easy jump into and to use, but even with today's tools the forefront of machine learning is a difficult field. A smart engineer can usually implement ideas by following formulas in papers, but does not have the mathematical background to develop them (hyperbolic geometry, functional analysis, dynamical systems, random matrix theory). On top of this, very few people and companies could actually afford to run extremely large and deep networks on several GPUs.
Corporations and Open-source
Google having several AI research teams, spent millions of dollars to develop its own deep learning framework. Soon Google started rolling out results of its research in products created on its custom platform such as Google+ Image search, and the enhanced Voice search, and Google translate. Facebook, Amazon, Microsoft and other companies were doing the same. However, on 9 Nov 2015 Google shocked the community by announcing the open source release of most of its Tensorflow platform. Seeing the largest tech companies go open-source is weird at first, but it makes perfect business sense. Around 2015 open-source started to boom at Facebook, Google and Microsoft but not because they suddenly felt an urge to be more communitarian, but because business has changed. Software is not the product anymore and Google does not give its users Gmail, Translate, Drive and other amazing product for free. The product is the user, its attention and all the data generated by it. The software became only a platform that lures in, captures and traps all the potential users. The revenue is generated by selling ads, using users’ data and driving traffic to other paid services of a certain company. The same has happened in the deep learning businesses, and Google was quickly followed by Facebook and Microsoft releasing the open-source version of their own software.
Results of open sourcing on Machine Learning
Google’s decision was completely rational and forward thinking. They created an open-source project, that is biased towards making developers use other Google services in a hidden ways.
The company would not gain any serious advantage by keeping its technology proprietary. In reality, Tensorflow is not superior to other libraries. The open field of deep learning frameworks is already a crowded and hyper competitive market. The traditional open-source scientific libraries (Torch, Theano) perform similarly to Tensorflow, and most research was published on them. Other platforms, such as CNTK (Microsoft’s take on machine learning) is far more scalable on large servers, and MXnet supported by Amazon is much faster to train. The underlying algorithms of Tensorflow were based on open-source projects and were always well known. Even if Tensorflow becomes a superior framework, and Google gives away these training algorithms to the competition, at the end of the day speed is not always the most important thing. The real algorithmic advantage lies in the implementation of the deep learning models like the one behind Alphago, the AI, which beat the world’s best Go player. Google has not given away these implementation specific algorithms. The real value of Tensorflow is in the engineering that runs those algorithms cross-platform and at scale across a wide range of devices from a cloud server, a desktop machine to a mobile phone. That's not a trivial feat by any stretch, but it also is hard to replicate. Overall, Google did not lose much from publishing yet another deep learning library, but gained tremendously from it.
The framework is not valuable by itself, but the people and the service built on top of it make it valuable. Google realized it, and tried to monetize on this idea. Tensorflow has by far the best documentation, largest range of additional tools, like Tensorboard to visualize data to help debug it, a visual representation of deep learning layers, widest support for potential devices that people might run their models on. With all this Google lowered the barrier to entry to reach as many developers as possible. In a hyper competitive and fast-evolving market, like machine learning, the only way to stay afloat and get ahead of the competition is to convince the future talent to use Tensorflow. If the smartest talent already uses Tensorflow, hiring and training them becomes an easy process. Similarly, if innovative startups decide to use Tensorflow as their framework, acquiring them and integrating them into Google becomes seamless. The more people use the platform, the faster Google can get feedback on new features allowing its engineers to increase their productivity, and have a more realistic picture of what the community really needs. Open sourcing and the transparency facilitates conversation between developers and people using the products, and creates confidence in people, which motivates developers, outside researchers and potential future hires to be dedicated to this platform. Obviously, by open sourcing, they get the benefits from contributors outside the core team. Once Tensorflow gets popular, many new research ideas would be implemented in Tensorflow first, which makes it more efficient for Google to productize those ideas and have advantages over competitors.
By having an open-source development framework with a strong community, Google will not make any profits. The company needs its community to create products that use its other paid services. Training deep learning models requires terabytes of data being run through computation heavy functions for days at least. Perhaps not surprisingly, the cloud giants that stand to gain from an influx of data-heavy applications are the same ones open sourcing their frameworks in the first place. Microsoft, Amazon and Google are all in the business of machine learning to drive business to their respective Microsoft Azure, Amazon Web Services and Google Cloud businesses. Currently, Google is a distant third in the cloud business, but they are betting heavily on the success of Tensorflow.
Open-sourcing this way does not make development distributed in any way, as most development is still made in-house. Google maximizes the number of developers using its platform, and uses its immense influence on the field and the developer tools to divert the flow of talent and traffic for other web services in its favor. They deliberately create an environment where it is easier to use Google Cloud, than for instance Microsoft Azure, and where it is easier for them to hire the best talent and where most cutting edge research would be native to Tensorflow. The bias, and open-sourcing serves Google’s best interests, but it’s not something that wouldn’t happen otherwise. If Google kept Tensorflow closed-source, they could still force people to use their cloud services even stronger, and once you learnt Tensorflow it would be hard to switch anyways. So the result is essentially very similar, but Google’s reach is extended and these actions also promote transparency.
While open-sourcing still serves Google’s corporate interests, the side effect is the democratization of machine learning. Through this open-source platform, everybody has access to the top machine learning algorithms for learning and research purposes. The lowering the barrier of entry, makes it incredible easy to learn deep learning as a beginner nowadays. The more people are familiar with the science of machine learning, the more people accept it and trust it as a new driver of our economy. In addition, having a high-tech platform with a great community increases scientific progress and collaboration. The only thing developers need to keep in mind is that wrapping software in the disguise of open-source, does not mean that it is a truly independent software effort. Developers need to keep in mind what package the software comes in.
Conclusion
We're effectively seeing a market where the rational behaviour is to spend lots of time and effort building something incredibly useful, and then giving it away for free. This was probably unthinkable just a decade ago, but business has changed quickly. When competitive market forces drive big corporations toward a model of "openness", everyone wins as long as it is easy to move between platforms.
Sources:
Ivakhnenko, A. G. (1973). Cybernetic Predicting Devices. CCM Information Corporation.
ImageNet Classification with Deep Convolutional Neural Networks https://www.cs.toronto.edu/~kriz/ imagenet_classification_with_deep_convolutional.pdf
Why Microsoft is turning into an open-source company, https://www.zdnet.com/article/why-microsoft-is-turning-into-an-open-source-company/
Why More Companies Are Adopting Open Source Technology https://about.gitlab.com/2017/03/03/why-choose-open-source/
Open Source Is Going Even More Open—Because It Has To https://www.wired.com/2015/07/open-source-going-even-openbecause/
Google Open-Sourcing TensorFlow Shows AI’s Future Is Data https://www.wired.com/2015/11/
google-open-sourcing-tensorflow-shows-ais-future-is-data-not-code/
Top 10 Deep Learning Frameworks https://datahub.packtpub.com/deep-learning/top-10-deep-learning-frameworks/
A Survey of Deep Learning Frameworks https://medium.com/towards-data-science/a-survey-of-deep-learning-frameworks-43b88b11af34
Tensorflow, An open-source software library for Machine Intelligence https://www.tensorflow.org/
2017 Gartner MQ for Cloud - Compare Top BI Leaders

Browsing Bias
Politics of Code - Gabor Csapo - 22. Oct. 2017
Faces in traditional media are mostly white and male, and the internet seems to abide by the same rules. In this project, I would like to create a tool that measures what portion of faces encountered during a regular browsing session is male/female, and what the ethnic background of them is. To achieve that, I will create a Chrome extension, that will collect links to every single image that a user encounters while browsing the internet. The extension will then send the list of links to a server that has a trained model on pictures of people, their ethnicity and gender, which would be able to classify the people on those images. This latter server side would use part of my capstone. Overall, the project would give a sense of to what extent is the internet gender and ethnicity biased.

Mytorch.tech Sprint 2
Politics of Code - Gabor Csapo - 22. Oct. 2017
In the previous prototyping stage Jihyun and I managed to get a grip of the problem and successfully materialized our idea into a functioning app. However, the devil lies in the details. Creating the outlines of an app nowadays is made really easy by frameworks, that do the bulk of the work, but perfecting the details and streamlining the UI is what usually takes up most of the time. We received some great feedback in class on how to improve and set our goal to increase the usability of our app to match our use case scenarios.
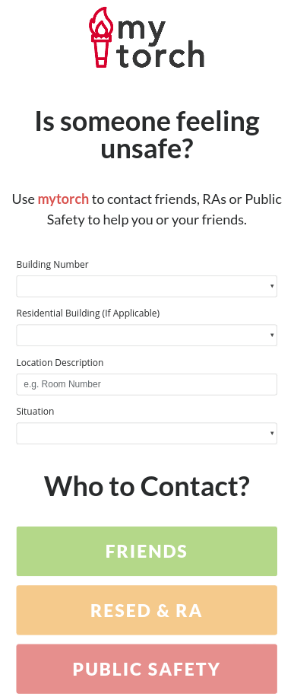
Initial improvements
We wanted to start off by getting feedback and validating our idea, but first it made more sense to implement the feedback we received in class. We set off to create splash page for first time user where they would input their friends’ phone numbers. We also managed to set up a Mongoose database for users, their friends’ numbers and records of incidents to filter out trolling mainly.
User testing
We interviewed a number of our classmates to validate and test our idea. We briefly introduced them to our project, and then we let them familiarize themselves with the app. Following that, we gave them a scenario and we watched how they navigated the UI to resolve the issue. Lastly, we asked them for direct feedback. We organized all the potential improvements on a Github board, which is a great tool that I have just heard about, but will definitely use it more in the future. We prioritized the tasks and created a sprint for the next 2 weeks.
Tasks
Tagline & rewording buttons & anonymity disclaimer
We had to clarify our intents. A number of people mentioned that it wasn’t clear at first sight what the app and the individual buttons were actually for until we explained it. This was our number one task to solve. Our solution was to come up with a tagline on the login page clearly portraying the purpose of the app, and a more accurate call to action on the main form submission page. We also forgot before to make it clear that the app is completely anonymous.
More straightforward formsA few people were a bit confused about filling in the forms, it was a lot of typing, people forgot to fill in the location form, it wasn’t actually clear which button to click on and on mobile devices everybody expected that pressing enter would take the cursor to the next text field, but with default HTML that is not the case. As a result, we completely redesigned the main page with more drop down choices, disabled buttons until the forms are filled in, split up the location text field into a number of dropdown options to speed up the input process. We also decided to send an HTML confirm() before sending out the SMS to public safety in order to make sure people are aware of the consequences. I also found code a snippet that made forms more mobile friendly.
Safety tipsThis section was the least refined in the initial demo, and we were looking for ways to make it more informative. We made it shorter, we have three blocks for them, we are not showing them at the same time anymore, we corrected some of the information that happened to be US specific. There are still ways to improve the contact. For example, we thought of having more visuals, but that would go into sprint 3.
Debugging & extrasThe app had a few minor bugs, like the menu didn’t work on smartphones, or the location wouldn’t go through in the SMS, etc… We found a way to have an anchor tag open up the phone dial with a preset number, so now you can call directly public safety if you need to clarify the situation. If the user has a phone number, we are sending that along the SMS, so that public safety can also directly call the student.
Moving forward
The app is not production ready yet. Mytorchtech is a lot of responsibility, and we would need to ask for funding, talk to public safety, student life, the SIG Reach, print posters, raise awareness, which as seniors we don’t have time for. A clear solution to the problem would be getting other people on board, and open-sourcing the project. We spent a significant amount of time commenting up the code, and writing a readme, so that anybody could pick up the project, and implement any of the extra feedback we received while presenting in Mashups, such as the ability to confirm that a guard is arriving, integrating facebook messenger into the app, and the list continues.

Machine Learning for Art
Politics of Code - Gabor Csapo - 22. Oct. 2017
Software can be more than an off-the-shelf product that is judged by its efficiency. It can both be and be used to create a new form of art, that opens up a myriad of doors. Recently, I became interested in algorithmic design, and finding minimalistic ways to create abstract, interactive graphics. As a result of this interest, I became fascinated by the A.rt I.ntel course offered next semester that explores the applications of machine learning for artists.
Recent developments in machine learning have been compared to the beginning of the industrial revolution. The steam engine has overcome the limitations of the human muscle, and people predict AIs to push the limits of our cognitive abilities. Leveraging the power of terabytes of data, sophisticated algorithms, and high performance computing, we can dedicate our minds to higher level thinking. Machine learning provides us with technical tools that aid creation, let’s say if you want to transform the style of your photographs to Van Gogh’s just run a deep style algorithm on it, if you wanted to create a caricature of politicians, you can make their faces move any way and talk using Face2face. Either of those, would have involved hundreds of hours learning photoshop, and animation, but this cognitive task can be automatized. I believe in the future, newer machine learning libraries will allow more and richer creation, which is why I would like to take the A.rt I.ntel machine learning art class next semester.
The new revolution can mean a significant shift in our understanding of art, as until recently art was understood as something innately human, which reminds me of a quote from the 2004 movie, I, Robot:
Human: “Human beings have dreams. Even dogs have dreams, but not you, you are just a machine. An imitation of life. Can a robot write a symphony? Can a robot turn a... canvas into a beautiful masterpiece?”
Robot AI: “Can *you*?”
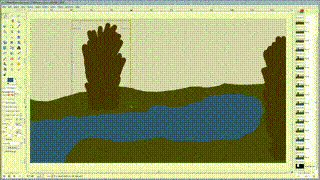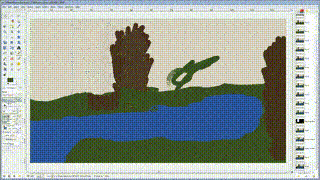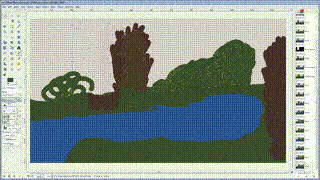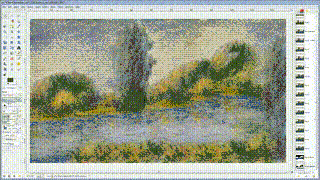

Applications of style transfer using neural nets.

Manipulation
Politics of Code - Gabor Csapo - 9. Oct. 2017
Crowd manipulation is a negative word. The word is usually used in the context of surveillance, gain of popular political power, and tricking the masses. However, I think, manipulation is, whatever we use it for. As Tufekci describes in his “Engineering the public” paper, a demagogue can apply social engineering techniques for anti-democratic purposes, but a good leader can reach socially desirable goals. Unfortunately, crowd manipulation is not a privilege of the political power anymore, moreover, they aren’t even the best at it. Social media businesses emerged realizing the potential of monetizing on the crowds.
Social media stood for the celebration of the individual, but ironically this hyper individualistic platform became the proof of how intertwined our lives are. It seems almost as if humans were merely a herd and governments/companies are constantly redrawing the fence around us, to benefit themselves. It makes me a bit disappointed that we have this massive power to push people towards doing good, to promote entrepreneurial spirit, volunteering, or to make diverse news reach everybody, but we don’t make use of it. After all business is business and the sole purpose of social networks is to crunch out as much money as possible from the collected data.
We are designed to be manipulated in our very nature. We respond to our environment, and adapt to changes. Every design decision of shaping our environment that affect the way we interact with our surrounding, is an act of manipulation. The change in our behaviour goes often unnoticed or we simply don’t care. People never really question if they receive more liberal or conservative articles for Google queries, which gives incredible power into the hands of software engineers who design the tools we use daily. Thinking about the huge impact software has on our lives, fires me up every time to make a positive contribution to society.

Electronic Governments
Politics of Code - Gabor Csapo - 4. Oct. 2017
The world is changing, but democracy is slow to catch up. While power, capital and information is increasingly concentrated in the cyberspace utilizing the benefits of efficiency and faster adaptability, democracy still uses methods inherited from the last century. Michael Mussman in his paper “Programming a Deliberative Direct-Democracy” touched upon a lot of thoughts that I’ve been baffled with.
In the first part of his paper, he compares governments to computer operating systems, as “[they both] have the ability to coordinate activity and delegate resources among the constituent parts of a system”. I absolutely agree that governments are the necessary facilitators of running businesses while they abstract and take care of issues such as security, justice, or education. This shows immense similarity with operating systems that provide an interface between the hardware and third party applications. In software engineering, it isn’t necessarily the hardware’s or the third party applications’ fault if they are crashing. Most likely the system that binds them together was badly designed or the wrong parameters were used. The same way, I believe in many cases failing governments are the result of an unsuitable system that prevents the ideal flow of ideas.
Political systems provide the breeding ground for ideas and the selection of the best ones. However, tweaking the environment can result in very different outcomes. As we discussed in the second week, urban planners have power over the behaviour of people through the design of space. Similarly switching from physical newsstands (that give a glimpse at all the available opinions as you stand in front of it) to facebook (where you get served only the information you subscribe to) greatly changed and polarized the ideological landscape. The same way, the people need to design a political system that cultivates a deep social network allowing the engagement of ideas instead of dividing and obstructing them.
As the “Civil Disobedience” paper argues, political power shifted from the physical to the cyberspace and activist need to follow it there. However, not just activist but the institution of democracy should also follow it into the new age. Political participation is failing in many countries, because new generations can’t engage with traditional elections and debates that we inherited from the last century. And hence crowd manipulators like Trump can get elected. While the older generation might be satisfied with traditional methods, and does not trust change, we have the admit that our world has changed, and politics is detached from it. We need to bring in new platforms to debate, data visualization to effectively express ideas, and decentralization to support new ideas. Technology needs to be better integrated into the political system and we need to create an environment that actively prompts the youth to think.

Mytorch.tech
Politics of Code - 25. Sept. 2017
Our team created mytorch.tech to resolve issues arising in the legal gray area of alcohol and other types of misconduct at NYU Abu Dhabi. The UAE being a Muslim country forbids residents including NYUAD student the consumption of alcohol with rare exceptions. Some students regardless choose to abuse substances, which puts them and the university’s reputation in danger. Residential education trusts students to be smart about their personal decision, but there are always people who don’t know their limits or can’t control themselves. Most years went by with a few incidents, but last year oblivious freshmen called the ambulance without notifying the school, which resulted in a legally difficult situation. The administration’s solution was to crack down on any dangerous behaviour. Mytorch.tech offers an alternative conflict resolution method, by opening communication channels to resolve conflicts by contacting the person in charge appropriate to the situation in order to avoid unnecessary trouble.
Mytorch.tech offers a web-based application streamlined to put the user in touch with the appropriate person in charge. For instance, a potentially escalating situation does not necessarily require the same level of intervention as alcohol poisoning or sexual assault. The app helps one make this decision by providing easy to read instructions, and making clear the consequences of each help option. The app avoids asking or storing information that could potentially get the user into trouble. By avoiding avoiding direct mention also prevents the service from any legal obligation to report the users for their behaviour. We don’t store incriminating information and if we were to continue the project, we would turn all data transfer encrypted and ephemeral.
My main contribution to the project was in the development steps. After we conceptualized the app together, we decided on the technologies we would use and starting materializing the app in just two weeks. Mytorch.tech is a node js application that renders the UI with pug. The app has the ability to contact people using the Twilio SMS API, look up addresses using the Google Location API and one can log in using the Google Oauth passport js module. My tasks were to build the login feature and the SMS capability, while also debugging issues encountered with heroku. Initially, I planned to use the official NYU login API, but after several hours of various attempts, I found an alternative way to login. My workaround was to login into the NYU provided google account and authenticate the user through that. Although it seems like a straightforward feature, it was not an easy process. I attempted to use directly the Google API and then Firebase with little success. In the end, passport js seemed the only working solution. To set it up, I had to learn about sessions, secure cookies, passport js and Google Oauth2. Setting up the SMS capability using Twilio was an easier task, as I used their service before. The project also required me to familiarize myself with Pug.
Mytorch.tech is an app that resolves accidental conflicts by opening up communication channels and informing user about their behaviour while dodging any legal trouble. While I expanded my web development skills, I also learnt more about the alcohol related topics on campus and every mention of this app to my friends received approval from them. Unfortunately, there are some issues we could not resolve due to our time constraint. The Google Oauth does not allow cross-domain origin login, which prevent us from masking the mytorchtech.herokuapp.com url into mytorch.tech. We will have to develop our own NYUAD specific location API, as Google does not provide information about our campus. Our current design is, however, a perfect demo to show officials to win support. After creating this prototype the next step would be to start a campus wide conversation about the usability of our app. We need to win the support of public safety, RAs and residential education. After receiving approval, we would extend the app with additional features such as encrypted ephemeral messaging and data transfers, further streamlining the interface, and ensuring the reliability of the app, so that it can always service the people in need. With every startup timing is the number one issue and based on the recent campus wide concern about alcohol related issues, this semester is the perfect time to launch our service.
Video Games for Learning
Politics of Code - Gabor Csapo - Sept. 25. 2017
Video games have enormous untapped educational potential. As I. Bogost argues in his “Rethoric of Video Games” paper, games create a limited possibility space by setting up rules, boundaries and constraints, and then players explore the countless options this world offers. On playgrounds, you can often see children giving out rules like “you’re the dad, you’re the mom, you cook!”. Once they have these rules, they explore what options the constraints allow, and what they think about the situation. This kind of discovery can be a powerful tool to express opinions and to critique systems.
Games like Sims and Grand Theft Auto fascinate me because they are able to create such expressive worlds. They manage to simplify complex, often random relations with hard coded if else statements, that overall capture the essence a simplified life. They show us the issues of criminal behaviour, or critique how our lives and personalities are dependent on the objects we interact with. But a game doesn’t have to be complex to have a message. The first example in the above mentioned paper, is Animal Crossing, which is a simple village life simulator, and an implicit critique of materialistic thinking and the financial bourgeoisie. Even a five a year old can see and question why the village banker gets richer and richer as you take out more and more loans so that you can buy a bigger house for all the items you collected in the game. By showing this, the game makes people wonder about the dynamics that exist in the real world.
The three main reason why games have potential as learning tools is that even children can understand them, which is the prime age of learning, they are fun so people do it on their own, and they provide a deeper engagement with theories. Video games are created by encapsulating a set of ideals and theories about a certain world through code, and inserting these biases into a digital space, where we are free to explore combinations of decisions. This procedural presentation of ideas provide a deeper experiential learning as opposed to linear media such as a book or a movie, where everything is laid out in a predetermined manner and you don’t get a chance to engage with its world.
If I was taught about computer science as a kid, I don’t think I would have liked it. However, I came across a game called Littlebig Planet, that captured my interest for a long time. It is a simple platforming game, but there is an incredibly intuitive level building mode, which is actually the selling point of the game. My level designs became very sophisticated as I learnt to utilize the tools provided in the game, which strongly resembled web and app design. The levels have logic boards, which receive inputs from switches and output signals to elements in the game that control the gameplay. One has to think about usability, design, reusability the same way as in software engineering, and I believe this simplistic presentation of thinking as a coder contributed to my interest in computer science.
I can’t think of a field that can’t be gamified. Politics, management, racing all found an easy ground into our entertainment habits through games, but I think many more fields can do the same if we make a conscious effort to have a positive impact through video games, and study how we can create expressive worlds. But to do that people’s perception of video games need to change, and they need to be taken seriously as simulations of our world that we can learn from rather than sources of entertainment for children.

Machine bias
Politics of Code - Gabor Csapo - 18. Sept. 2017
“The blind application of machine learning runs the risk of amplifying biases present in data.” The number one task of modern data analytic tools and machine learning is to recognize meaningful patterns in data. We spent thousands of hours trying to make sure our algorithms can differentiate with 100% accuracy cats and dogs, but in the process we also created machines that recognize patterns in data that are not meant to be there.
Every machine learning tutorial starts with making sure your training data has an even distribution with no biases. However, based on recent readings, data that describes humans will likely also capture our biased nature. We thought algorithms are pure rationality, but as we increasingly take heuristic methods and train algorithms on human data, they seem to become the victims of human biases. As the paper “Man is to Computer Programmer as Woman is to Homemaker?” points out even news corpora curated by professional journalists is characterized by our everyday gender bias. It is important to notice, because if we train a natural language processing model based on that dataset, we will end up with an undesired, gendered computer model of our language. Such a model is Word2Vec, which transforms words into vector in order to describe their similarities and to help natural language processing. Google trained a Word2Vec model on a biased news corpus, which has been widely applied in hundreds of production software and projects. Such software only amplifies the existing biases in our society.
As computers software becomes more and more complex, we start to believe algorithms, which we don’t understand anymore. Technoscience with its machine predictions increasingly overtakes traditional scientific reasoning, where cause and effect explanations dominate. Most of our financial decisions on the stock market are done by algorithms nobody understand anymore. They are merely data hungry databases that crunch out the best possible investments in milliseconds. While it is a bit troublesome that our economy could easily crash because of a faulty algorithm, machines are generally good with numbers. The problem is when we give these same machines ethical jobs to do.
The US government has created a sort of social network of terrorist based incredible amounts of data collected about the interactions between people among large populations. They have a database where they feed data, and cluster it, and hope to discover patterns and anomalies that indicate terrorist activity to ultimately nominate people to kill. This data hungry giant bases life and death decisions on computed possibilities instead of facts, and these possibilities are becoming harder and harder to justify as the algorithm grows. The other problem is that it is based largely on heuristics, which introduces naturally a large error margin. If we look at only who these terrorists interact with, often family members and friends are also nominated on the killing list. Is this wrong or does it serve society? Hard to tell, but it portrays a rather grim future to me where machines know everything about us. For instance, just like in a scifi movie, in the future if you don’t eat an apple in the morning, you can expect a message from a robot that sort, recycles, and look for patterns in your trash, that you need more vitamins. I’m not sure if I want so much control over my decisions.
Too bad machines don’t have ethics yet. For now machines are still created by humans, so we should make sure we fight undesired biases in the process of creating our future. That is why I immensely admire the research presented in the “Man is to Computer Programmer as Woman is to Homemaker?” paper.

Abstraction from the Machine
Politics of Code - Gabor Csapo - 11. Sept. 2017
On Software, or the persistence of visual knowledge, by Wendy Hui Kyong Chun tackles the questions posed by the increasing abstraction of software from the machine. As Friedrich Kittler argued earlier “there is no software” because everything reduces to voltage differences as signifiers. Nonetheless we can drag windows from one side of the screen to the other as if they were real physical objects. To enable this level of abstraction from the physical machine, the computer had to learn how to manage itself and the lower level processes.
Today’s automatic programming arose from the desire to reuse code and to use the computer to write its own code. I was always curious who invented symbolic programming, where we simply write variables that represent numbers in the way everybody understands them. The history of automatic programming seems like an fascinating journey pushed by two world wrecking wars, where women have interesting symbolic role.
In the 50s programming was a feminine, clerical job (not yet a profession) where scientists would command women to input computations to the huge computers they had at that time. As Wendy says “One could say that programming and software became software when commands shifted from commanding a “girl” to commanding a machine.” Assembly was invented, so instructions could be written by the men in a human readable way. That is how women were eliminated from the industry for a long time and programming became culturally a masculine industry.
As Wendy discusses, software engineering’s purpose is to speed up the process of abstraction, to hide the machine and secure it from the programmer itself. You no longer needed black magic to understand the computer, as it became a black box, ultimately democratizing programming for the masses. Today we arrived to an age where most users have no idea how computers work. Even people creating software no longer understand the computer, because each software builds upon an older one, which builds upon another, etc... Creating an endless chain distancing humans from the computer, but freeing the user and the programmer from “suffering through the mastering of computing” (Rob Kitchin, Nature of Software).
As the writer explains, software becomes identical to an ideology: an imaginary description of reality, giving an idealistic explanation for the nature of the machine.
My favorite quote from the reading is a funny irony about the contradictory development of software: "As Our machines increasingly read and write without us, as our machines become more and more unreadable, so that seeing no longer guarantees knowing (if it ever did), we the so-called users are offered more to see, more to read. The computer - that most nonvisual and nontransparent device - has paradoxically fostered “visual culture” and “transparency.”"
Apps for a better Campus
Politics of Code - Gabor Csapo - 11. Sept. 2017
App ideas to improve life on campus:
1: Music Request System for Dining Hall and Gym: an online queue and voting system to request music to be played in public spaces instead of the current generic music. Students would see the current song on a web app, could up or down vote it, or request a new songs. Users are banned if they submit explicit songs. Potential issue: copyrights, getting dining hall and the gym on board.
2: Using a sensor or transaction data, we should figure out when are the popular times in the dining hall to prevent people from queuing.
3: Meal swipe market place: offer meal swipes for sale to people without stipend or people who eat a lot.

Seal Project
Information Visualization - Gabor Csapo - 2016/2017
Seal-Project - Visualizing Multivariate Ocean Data with Multiple Views.
Approached the Center for Sea Level Change looking for project ideas for a class. The head of CSLC asked for help to create a visual analysis system for salinity, depth, temperature data collected by tags put on seals in two fjords in Greenland. The project will help scientists better understand fjords and the melting of glaciers through novel visualization techniques for the temporal and spatial aspects of CTD data. I built the visualization using D3 JS.
How to use:
The prototype of the project is available by clicking on this link
See how an earlier version worked here

CTEXI - taxi by SMS
Software Engineering - Gabor Csapo - 22. May 2016
Transportation poses a huge issue in developing countries. Due to the lack of road infrastructure, efficient communication channels and reliable providers getting around in these countries can become a hassle. Our project aims to improve a specific segment of transportation: taxis. Following Professor Nyarko’s recommendation, we set as our short term goal to create a prototype of an Android app, which allows users to book cabs through text messages (SMS). The system allocates the closest available cab driver to the user and shares essential information to provide a faster and more efficient service. The service has the potential of becoming the dominant player in the taxi industry in Ghana.
The team
- commits made by gc1569 and STUDENT are Gabor
- wld224 Leigthon
- ma3585 Muaz
Releases
First
- Has the basic UI implementation, with buttons leading to the correct pages
- Displays a static response when driver is requested
Second
- Along with a slightly improved app, we also have a basic NODEjs server
Third
- The app was heavily improved to accomodate request and responses from the server
- The server is not up to serve data to the app yet
Fourth
- The app has access to location data, and sends and receives SMSs
- The server accomodates requests, but doesn't store and match participants
How does it work?
The problem with the current taxi booking system lies in its decentralized and inefficient nature. As explained by Prof. Yaw, taxis usually wait for their passengers at taxi ranks and the only way to request a pickup is through a human operated dispatcher center. In the current system people have to go to the city center and wait for a long time for their cabs. The application solves this problem by providing an automated central allocation system, which matches each customer with the closest taxi driver, who can pick up the person at any desired location. We have the following functionality requirements for the prototype:
The Rider
- Downloads app, inputs his/her contact information into local database
- Clicks on “Book taxi”
- Writes a short message to specify location (i.e. opposite of the school…)
- “Requesting cab” sends the GPS coordinates and the message to the server via SMS
- Server allocates driver and sends back driver’s name and phone number via SMS
- If further specifications are needed the two parties can call each other
- Taxi arrives to the set location and takes the user to the destination
- Mobile or cash payment
The Driver
- Downloads app and registers as a driver
- Sets availability to yes
- Waits for a request to arrive
- Request comes in with the pickup location shown on an offline map
- Sends estimated time of arrival and confirmation via SMS
- Picks up the customer and drops off at desired location
- Receives payment via mobile transfer or cash
- Waits for the next request
These two sets of functionality will be implemented in two separate apps using the same back-end to communicate with a central server by SMS. Initially we intend to develop the "rider" app interface for Android phones, and then implement the "driver" interface other aspects of the project if time permits it.
Modifying the app
If you would like to edit our code, you need to install Android Studio along with the Android SDK and the Java SDK. Once you have these, clone the project and go to --> Select File | New | Project from Existing Sources from the main menu. Browse to the project that you'd like to import and click next Choose to "import the project from external model" Android Studio walks you through all the steps to successfully import the project e.g. importing external libraries, dependencies... Then you have to download "Volley" Next, you have to comment out from volley build.gradle the line "apply from: 'bintray.gradle'" And go to File --> New --> Import Module --> [select location] and name the module "VolleyX"
Details on what each class and function does can be seenin the code. I don't want to create an object diagram, because the purpose, functionality and number of objects change frequently.
The Server
The server runs on node.js. Currently it takes data over IP, but eventually it will be switched over to SMS.
It takes in data in the following format, where the message could be the name, or the message, depending on the request type.: [type]|[latitude]|[longitude]|[phone#]|[message]|[name]
Types of request:
- S : Driver sends GET request to ask for a rider, response should be the rider he was matched with
- U : Driver sends POST request to update his location in the database
- D : Driver sends POST request to let the server know he accepted or declines the deal. The info of the driver shoudl be sent to the rider
- R : Rider sends GET request to request a driver
While its functionality is being developed, the server will send a reply with information about the request, but once it is fully functional the responses will be limited to riders' requests.

Islamic Terrorism
Islamic Terrorism - Gabor Csapo - January 2017
Over the course of January 2017 I had the chance to take part in a class on Islamic terrorism. The class was full of intense discussion, heavy topics and the result of the class was a number of papers that try to grasp the problems of the Middle-East as of 2017.

Nepal & Revolutions
Revolutions and Social Change - Gabor Csapo - January 2015
Nepal is a little known country in South Asia. What's even less known is that the bloody revolution wrecking the country has just ended a decade ago. After taking a class that took its students to Nepal to interview the former PM there and soldiers, and taking a class on revolutions, I wrote two papers. One is on the causes of the revolution and the other on whether one man can create a revolution in the context of Soviet revolution.

DIYDJ
Interaction Lab - Gabor Csapo - 6. Dec. 2016
DIYDJ is a human computer interaction experiment, where the user interacts with a website through 3 separate interfaces to twist songs in fun ways. check out my project from my Github!!
The project is made up of three parts:
1. The website grabs and plays songs from Soundcloud, using Tone JS manipulates them, using P5.dom tracks colors, which is used as one of the inputs for the sound manipulation, using P5.speech recognizes if the user says “reverse” and reverses the song. I spent a significant amount of time on designing a pretty interface.
2. The arduino yun controller is a box with a battery that sends signal over wifi to the server to change the sound being played on the website
3. The server is set up using Node JS, hosted on Heroku, so it is publically available.
Ideation
The project is inspired by my midterm project but it is upgraded in every sense. In the midterm project I was looking for fun ways to manipulate sound, which turned out to be harder than I thought. I consulted with Luisa and in the end we agreed that playbackrate, pitch and filters are the best ways that are still manageably hard. This time I wanted to create fun interfaces to manipulate the sound with. I was thinking a lot about meaningful, fun and novel interfaces and I concluded computer vision, speech recognition and a wifi enabled controller is the best. Research and Development
I started my research with looking up technologies that are capable of achieving my goal. Last time I made the mistake of spending too much time on the wrong library. I didn’t want to make the same mistake. I’m still using Soundcloud as my source of songs, the layout is achieved using Bootstrap, Jquery. The server is built using Node JS and is connected to the website using Socket IO. The new technologies are:
P5 (Processing part): My original plan was to use the OpenCV Processing library to capture and use facial expressions as input for the website. However, I realised that it would create a cluttered platform with a website that is publicly available but only working with a program that one has to download, which didn’t make sense to me. Since the class is all about meaningful interactions between humans, the physical and the digital world, I thought it would be great to take a step forward from computer programming to web programming so that I can easily share my creation with others. I did sketches in Processing and they worked fine, but for the above mentioned reasons I decided to switch to the web version of Processing, P5 JS. It is technically the same thing as Processing, so as I discussed with Prof. Moon, it fulfills the processing part of the final assignment. I’m using P5.dom for capturing video and color tracking and P5.speech (created by NYU) for speech recognition. They are fairly straight forward libraries, so I only had to fix some minor bugs. Although the speech recognition doesn’t produce the best results. With the color tracking the biggest problem was that objects change their colors in different light scenarios. As a solution I included a control panel, where one can dynamically set the color being tracked.
Arduino Yun: I wanted to create something more technical for the arduino part than what I had before. Creating a battery powered Wifi enabled Arduino sounded like a good challenge and a useful skill since in the real world we would never connect an embedded device to a computer. I built a simple cardboard box for the parts to make it less messy. I big lesson I learnt is to learn to read emails, because I didn’t know the laser cutting is shut down after Dec. 7. And I made an appointment for Dec. 9 so even though I made a crazy cool box with an interesting pattern, I couldn’t laser cut it…
Lessons learnt:
My biggest take away from the project is that computer vision and speech recognition isn’t necessarily as hard as I thought. There are high level libraries available that make everything fairly easy, but once I want to alter something I have to dig really deep into the topic.